UPDATE (2007-10-20): I have since improved the algorithm described here, and made the improvements available in a follow-up article.
I recently decided to test how well the regular Windows heap allocator (the HeapAlloc group of functions) fares in multi-threaded and multi-core scenarios. The information I had previously been exposed to made me suspect that the regular heap allocator might suck. However, I could think of ways to implement a heap allocator that I thought shouldn't suck for multi-threaded and multi-core use. Further, in order to test whether the regular heap allocator sucks, you need something that doesn't suck to compare it against. So I decided to write my own concurrency-friendly heap allocator.
My implementation, OctAlloc, is based on non-locking, non-blocking, interlocked single-linked lists. The entire implementation uses no critical sections, mutexes, or locks whatsoever. It is based entirely on InterlockedCompareExchange64() and similar functions.
I envisioned that OctAlloc should be good for the most demanding and long-running applications, which means it cannot suffer from fragmentation problems at all. Fortunately, this is easy to achieve since a common fragmentation-free approach is simple and fast. Instead of allocating exactly as much data as the using code requests, have a number of standard sizes, round up the requested size to the nearest supported one, and allocate all requests for a certain object size from chunks of virtual memory dedicated to that size. This is called the buddy algorithm and of course, like most things, it is somewhat obvious and has therefore been around for long before I thought of it. :-)
The buddy algorithm makes sense for allocations up to a certain object size. In my case, I used the Windows allocation granularity (64 kB) to dictate that threshold. All objects at most 32752 bytes in size are allocated with the buddy algorithm. All allocation requests larger than that are passed directly to VirtualAlloc(). It makes no sense to pass smaller allocation requests directly to VirtualAlloc(), because that would mean allocating at least 64 kB no matter what the object size.
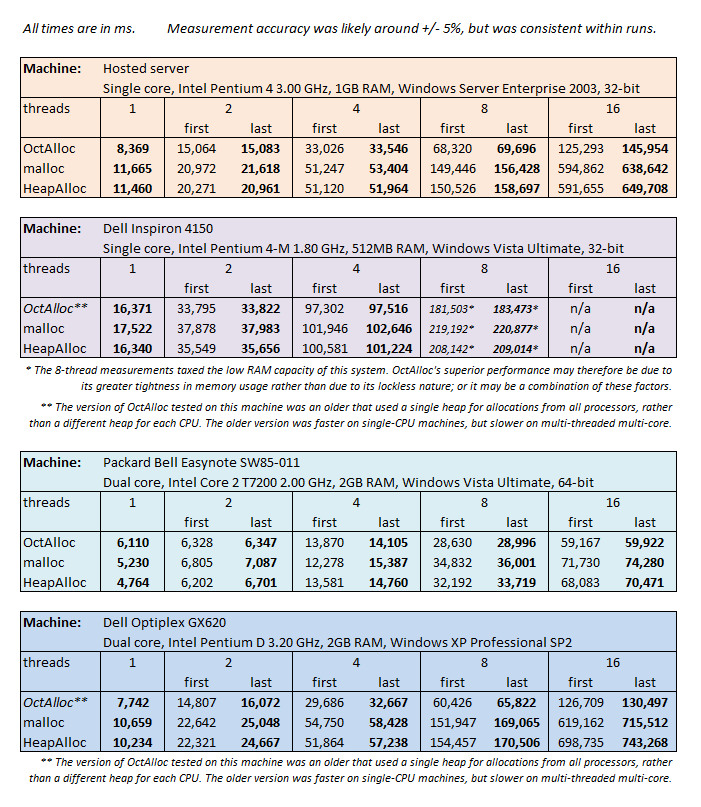
After I implemented the algorithm and tested it against HeapAlloc on multiple machines, my findings are as follows:
- OctAlloc is much tighter when it comes to managing its memory and releasing it back to the system. After a brief and heavy allocation stress, the memory consumption of HeapAlloc increases substantially and never falls back to the previous level. OctAlloc, on the other hand, dutifully releases unused virtual memory back to the system, the performance penalty for which is negligible. Given the clear advantage of more memory being available to programs that need it, I don't see why the Windows allocator doesn't behave more frugally with regard to the virtual memory it accumulates. There appears to be no excuse.
- OctAlloc is significantly faster than HeapAlloc on Windows XP and Windows Server 2003. It becomes in fact substantially faster as more threads compete for memory allocation, whether on a multi-core or single-processor machine.
- On the other hand, the default allocator in Windows Vista seems to be much better than the one in Windows XP and Windows Server 2003. On a single-processor machine, the default Windows allocator executed as fast as the initial version of OctAlloc. It does waste more memory for the same effect; but it is fast.
- But furthermore, the default allocator on Windows Vista totally kicks ass on multi-cores! In single-threaded use on a multi-core machine, it executed as fast as OctAlloc. But as soon as there was more than a single thread, it beat the initial version of OctAlloc hands down.
I therefore improved OctAlloc to remove what I thought was a bottleneck. OctAlloc allocated objects from an array of 53 buckets. However, the tests I was conducting were much heavier on small objects to mimick real-life use, so I figured the smallest buckets must be getting hit very frequently, so the two threads on a dual-core CPU must be competing for access to those buckets.
The solution I am using to synchronize bucket access is minimal as it is - it consists of a single InterlockedCompareExchange64() intrinsic, so I could see no way to speed this up. I was not convinced that another approach, perhaps a critical section with spin count, would have performed any better; the problem wasn't that the synchronizing algorithm is inefficient - it was that the cores had to synchronize in the first place.
My solution was to remove the need to synchronize by having each processor allocate new objects from a separate set of buckets. This does not prevent threads from sharing objects with other threads; a thread is still perfectly free to release an object allocated by another thread, even on another processor. The difference is, however, that there is now less contention during allocation: in allocation, a processor needs to compete only with frees being executed on the same bucket simultaneously by another processor. In the case of my test suite, where allocated objects were always freed by the same thread, this means that there should be no contention at all.
There is, however, a cost. Unfortunately, Windows still appears to provide no efficient way for a thread to query the number of the currently executing processor. Windows Server 2003 introduced GetCurrentProcessorNumber(), but the slowness of this function is horrendous. Its cost may be acceptable for other types of use, but using it for every heap allocation pretty much doubles the cost of allocation, defeating the purpose of using it at all. I therefore had to come up with a caching mechanism, which means the use of TlsGetValue() for every call to OctAlloc(). Furthermore, the OS does switch threads between processors over time, so the CPU number has to be periodically refreshed. This means a counter per thread, which means I needed TlsSetValue(), too. Also, because GetCurrentProcessorNumber() is not available prior to Windows Server 2003, I'm using the CPUID instruction to get the Initial APIC ID of the processor, which is just as unique.
As a result of this optimization, OctAlloc is now 25% slower than HeapAlloc when executing on a single thread on a multi-core CPU. However, it is also somewhat faster than HeapAlloc when multiple processors are simultaneously competing for heap allocation.
Because the multi-core optimization is not performed on single-processor CPUs, OctAlloc is still as fast as the Windows Vista HeapAlloc there; and of course, it remains substantially faster than HeapAlloc on either Windows XP or Windows Server 2003.
The following is a compilation of test figures I collected in my most recent tests. As you will notice, the results for malloc are very similar to HeapAlloc; this is because the Visual Studio 2005 version of malloc uses HeapAlloc internally.
I would be interested to see how OctAlloc performs on Windows systems with 4, 8, or 16 processors. If you have access to one of those and are willing to run a test, please let me know!
You can also download the source code and compiled test binaries:
OctAlloc.zip (52 kB)
UPDATE (2007-10-20): I have since improved the algorithm described here, and made the improvements available in a follow-up article.
This post does not yet have any comments.